Understanding AWS Instances

As of October 2023, AWS (Amazon Web Services) boast over 700 instance types to choose from, the largest of any cloud provider; starting in August 2006 with the m1.small instance types with 1vCPU and 1.7GiB of RAM, technology has come a long way to the latest generation 7 of Intel and AMD instance types.
Over the past 17 years, much has changed regarding how instances operate, with the AWS Nitro System accelerating innovation and being the standard behind instances in recent years.
AWS Nitro is a dedicated hardware and software system running per physical host, enabling secure virtualisation. The Nitro System allows AWS to allocate practically all of the compute and memory resources of the host hardware to a customer instance, and dedicated hardware enables high-speed networking, EBS (and I/O acceleration.
AWS has completely re-imagined our virtualization infrastructure. Traditionally, hypervisors protect the physical hardware and bios, virtualize the CPU, storage, networking, and provide a rich set of management capabilities. With the Nitro System, we are able to break apart those functions, offload them to dedicated hardware and software, and reduce costs by delivering practically all of the resources of a server to your instances.
https://aws.amazon.com/ec2/nitro/
The following diagram shows how the Nitro system controls a host system, implemented using onboard PCIE cards. VPC (Virtual Private Cloud), EBS (Elastic Block Store), and NVMe Nitro cards expose devices to provisioned instances through PCIe attachments, removing IO responsibilities from the Nitro Hypervisor.
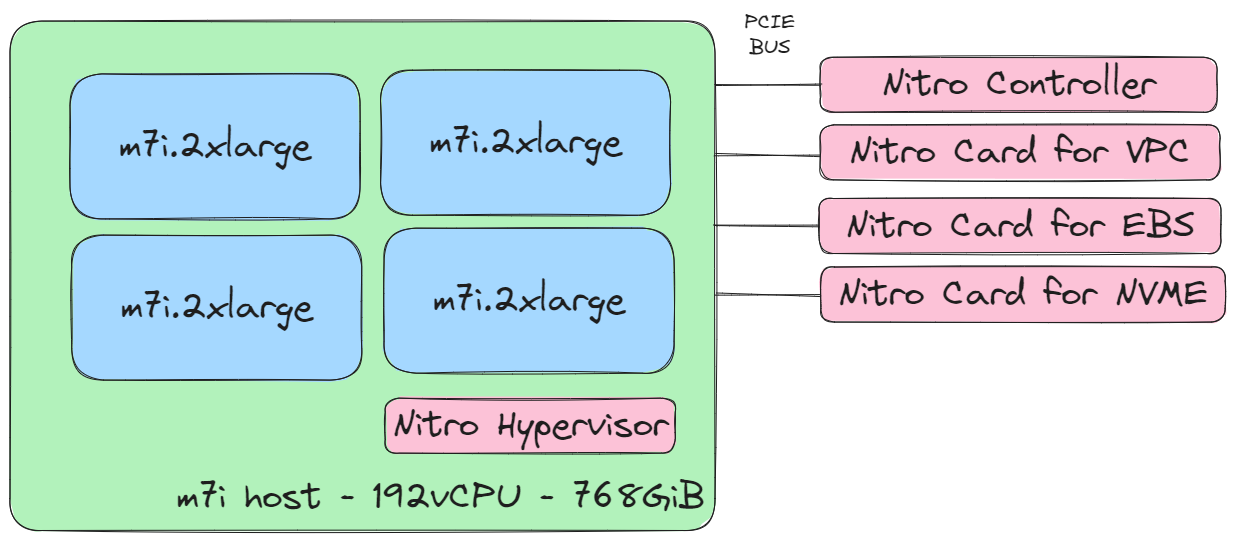
For an in-depth whitepaper on the design and security provided by the Nitro System, read The Security Design of the AWS Nitro System Whitepaper.
This article will primarily focus on the last few years of instance types, known as the "Current Generation". Older instance types such as the m1, t2 and m3 are more prone to edge cases than the more unified nature that the Nitro System now provides, but many of the concepts remain the same.
What is a vCPU?
Before jumping in, we must understand what an AWS vCPU (virtual CPU) means. The term vCPU is used throughout AWS documentation and can mean different things. For Intel and AMD instance types, a vCPU is a single thread of an x86-based processor core; for example, 2 vCPU is equivalent to 1 physical CPU core (running two threads). All recent x86 instance types come in multiple of two vCPUs.
For Graviton instance types, 1vCPU represents a single core of an AWS Graviton processor. This is standard for the ARM architecture, where single-thread cores are commonplace for simpler CPU design.
Older instance types have some exceptions to the above rules. The "CPU cores and threads per CPU core per instance type" documentation covers the CPU Cores and Threads per Core in detail.
Why so many letters?
Over the past few years, AWS has been developing a standard for its instance-type naming convention. Current generation instances now have instance types which explain in detail their capabilities.
The first position consists of the instance family, for example, Compute Optimised, followed by instance generation, processor family (a = AMD, i = Intel, g = Graviton), then additional capabilities (n = network/EBS optimised, z= high performance, etc). Finally, after the period comes the instance size, for example, small, medium, or 12xlarge.
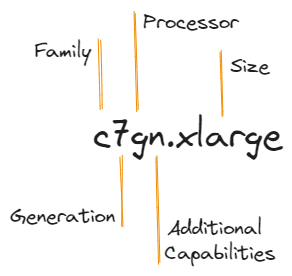
The best place to find the most up-to-date information regarding available instance types and naming conventions is in the EC2 Instance Types Documentation.
What is an instance?
As previously mentioned, AWS uses their Nitro system to provide hypervisor functionality. A hypervisor manages virtual machines on a physical server, allocating physical resources to virtual guests (instances).
CPUs have specific extensions (Intel VT-x and AMD-V) which enable virtualisation support. These extensions, virtualisation-aware memory management and IO devices can provide near-host-level performance whilst fully isolating guests from each other. Enabling cloud providers to run completely different customers on the same underlying hardware securely.
Subsequently, virtualisation technology can allow for much better resource allocation and simpler hardware deployment methodologies. No longer do datacenters need to have hardware containing 2CPU and 4GiB RAM. Instead, deploying high-spec servers and using virtualisation to split the resources is more effective.
For example, let's take the c6a instance type, which has multiple configurations up to c6a.metal. In the data centre, this c6a host will contain 192vCPU and 384GB of RAM, and any instance you launch will take up a portion of an underlying host of that full size.
For fixed-performance instances, the Nitro hypervisor pins hardware resources to your instance. "The CPU cores are not used to run other customer workloads, nor are any instance memory pages shared in any fashion across instances" - See The EC2 Approach to Prevening Side Channels.
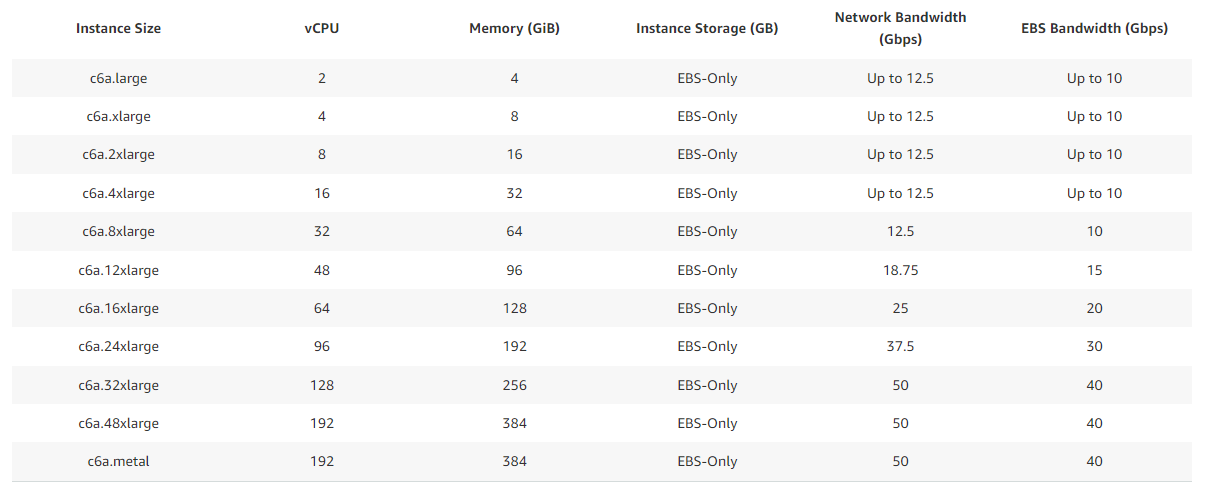
Behind the scenes, AWS systems need to bin-pack the instance types onto physically deployed hosts to ensure hosts are fully utilised. The bin-packing logic must consider various factors such as Availability Zones, specific billing or reserved host/instance requests, current usage across the instance family, current allocation available on hosts, schedule maintenance, etc. For example, different customer instances could be allocated to a single host in the following way:
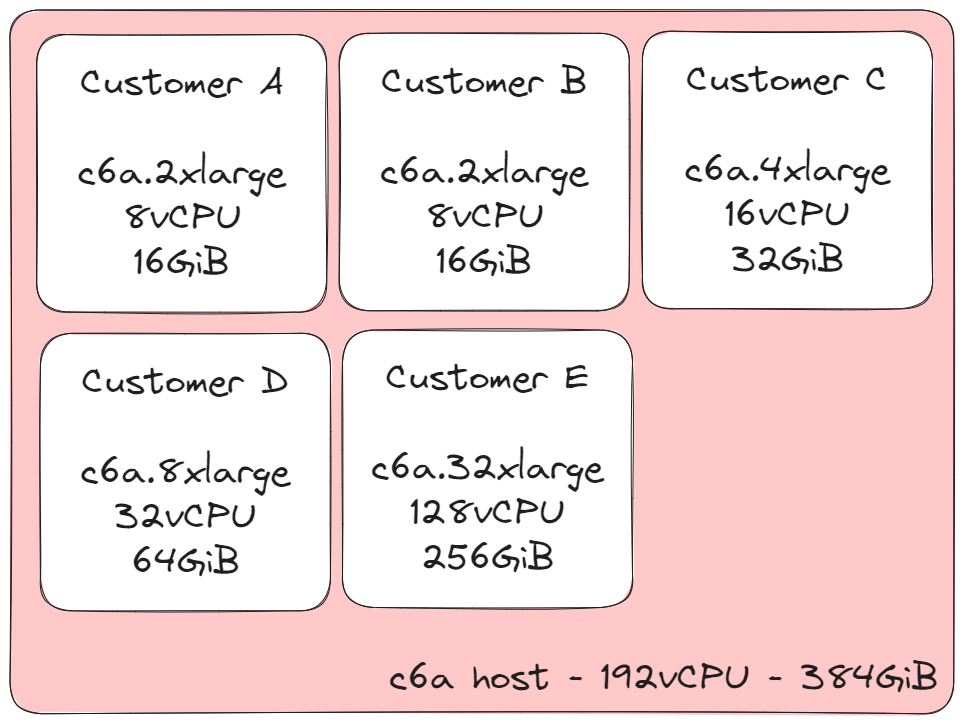
We can see here that all the instances running on this host add up to 48xlarge size, a total of 192vCPU and 384GiB of RAM. Another interesting, perhaps predictable, factor with instance pricing is that the cost is directly proportional to your instance size, for example:
The c6a.xlarge is $0.1530/hour
$0.1530/hour (xlarge) * 48 = 48xlarge = $7.3440/hour
=== The price of a c6a.48xlarge/metal instance type
Cloud providers use multi-socket hosts to utilise physical space effectively in the data centre, where a single motherboard is installed with two physical CPUs, and the RAM is shared equally between the CPUs. When working with instances allocated with multiple sockets, programs should be NUMA (Non-uniform memory access) aware, allowing CPUs to request local memory locations instead of those owned by the other CPU socket.
A more realistic scheduling system would also need to consider the underlying CPU sockets of a host. Here is the above workload with CPU socket allocation considered.
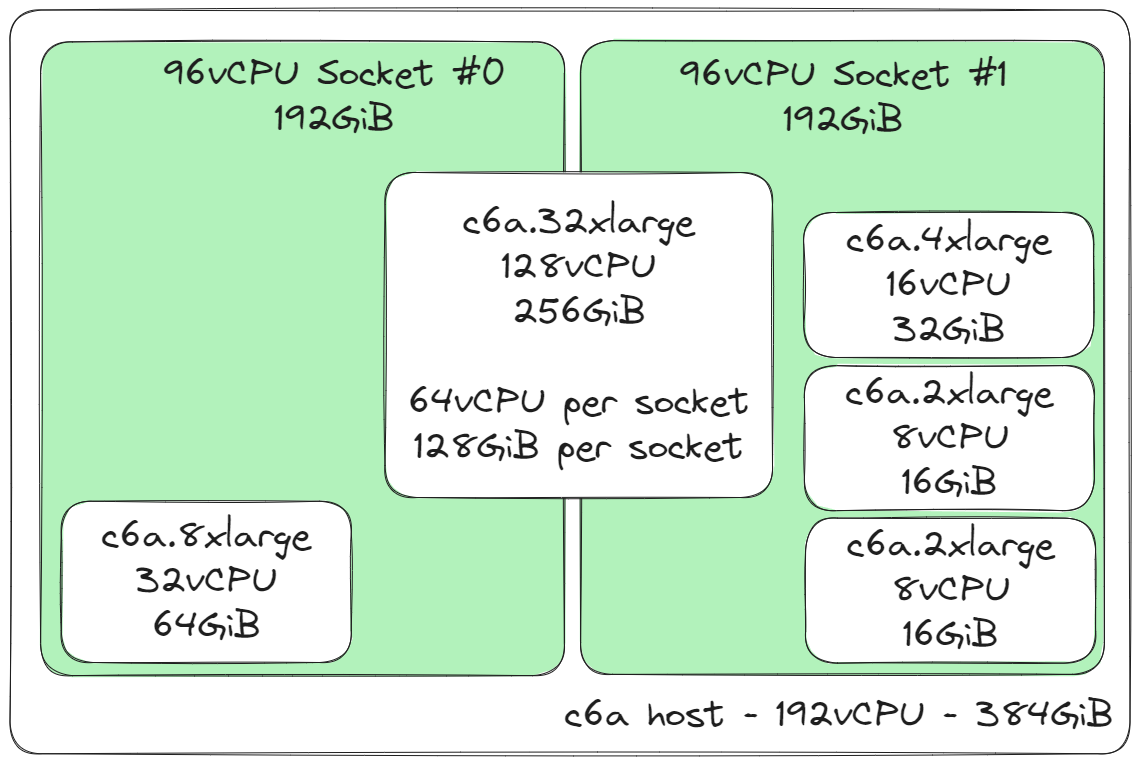
The c6a.32xlarge instance size must be spread equally across both CPU sockets, and this is because the allocation of vCPUs is greater than a single socket can provide. When an instance size is equal to (ex. c6a.24xlarge) or less than a socket vCPU capacity, it will be scheduled to reside within a single socket (and not be shared across multiple sockets).
We can see above how this instance packing allocates 96vCPUs per socket with 192GiB RAM allocated per socket. Other factors, such as guaranteed and burstable network and EBS throughput, must be considered during scheduling to fully allocate the host, which results in total revenue of the respective c6a.48xlarge or c6a.metal hourly cost, split across several instances/customers.
Instance Deep Dive
With the recent lineup of instances, it's clear that generational hardware is largely consistent across instance families within a specific generation, allowing AWS to install lots of mostly identical hardware, with the only difference being the amount of memory installed and any additional features provided by the nitro system, such as enhanced networking.
As an example, let us take a look at the latest c7i instance types, powered by custom 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) with an all-core turbo frequency of 3.2 GHz (max core turbo frequency of 3.8 GHz).
As usual, we have a list of instance sizes for large to 48xlarge available and two metal instance types that we will discuss later.
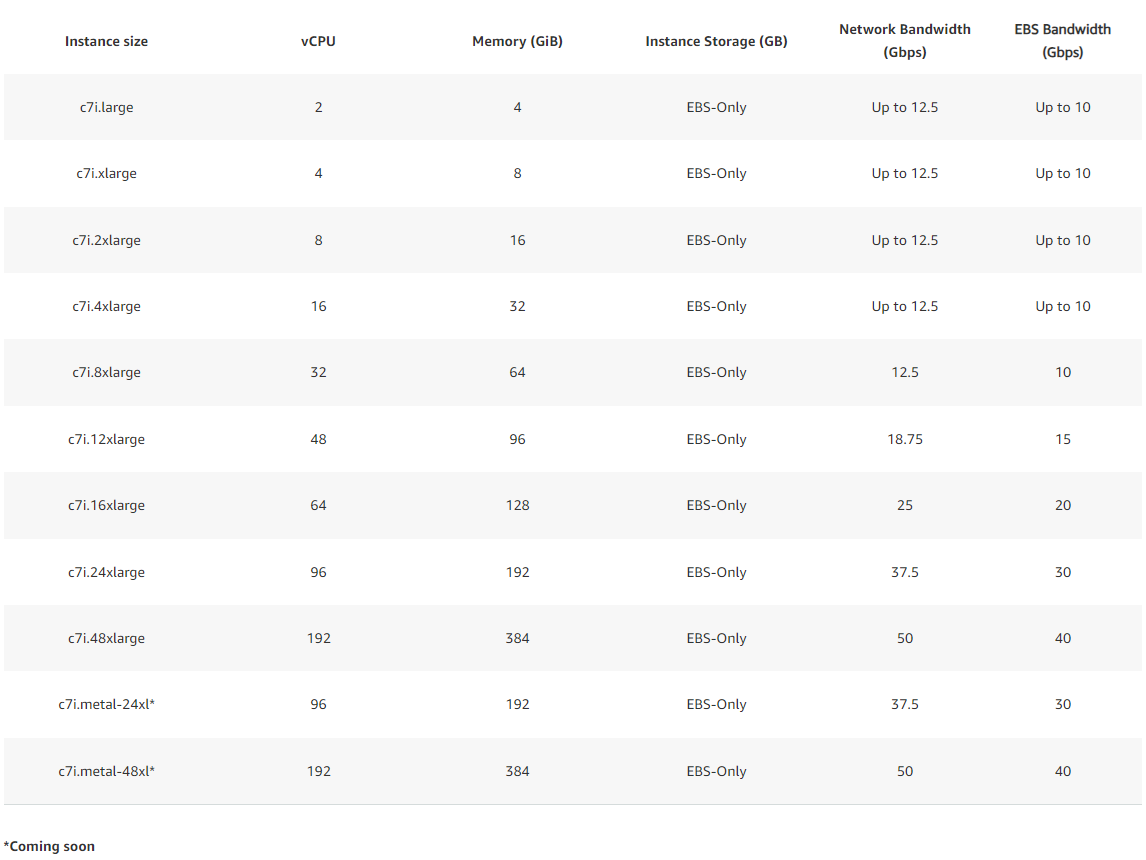
Running lscpu on an m7i.48xlarge or c7i.48xlarge, we can see the following identical output:
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 192
On-line CPU(s) list: 0-191
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Platinum 8488C
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 48
Socket(s): 2
Stepping: 8
BogoMIPS: 4800.00
Flags: ...
...
Caches (sum of all):
L1d: 4.5 MiB (96 instances)
L1i: 3 MiB (96 instances)
L2: 192 MiB (96 instances)
L3: 210 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0-47,96-143
NUMA node1 CPU(s): 48-95,144-191
This shows us the underlying hardware of these instance families:
- 2 CPUs (dual socket) Intel(R) Xeon(R) Platinum 8488C CPUs
- Each CPU has 48 cores / 96 threads (AWS vCPUs)
- A total of 96 cores / 192 vCPU available in the instance
- Runs the same CPU for m7i and c7i instances (and likely r7i when released)
Comparing the c7i to the m7i, we can see the only difference is the memory allocated to the instance. Network Bandwidth and EBS bandwidth scale identically with vCPUs against both instance families.
Some readers may have noticed that the network and EBS throughput mentioned above do not increase in direct proportion to the number of vCPUs. This design allows medium-tier instances to enjoy greater bandwidth compared to a strict proportional scaling. The diagram below illustrates various vCPU/Memory bin-packing configurations, showing that the total Network and EBS throughput remain consistent even when multiple instances are consolidated onto a single physical host.
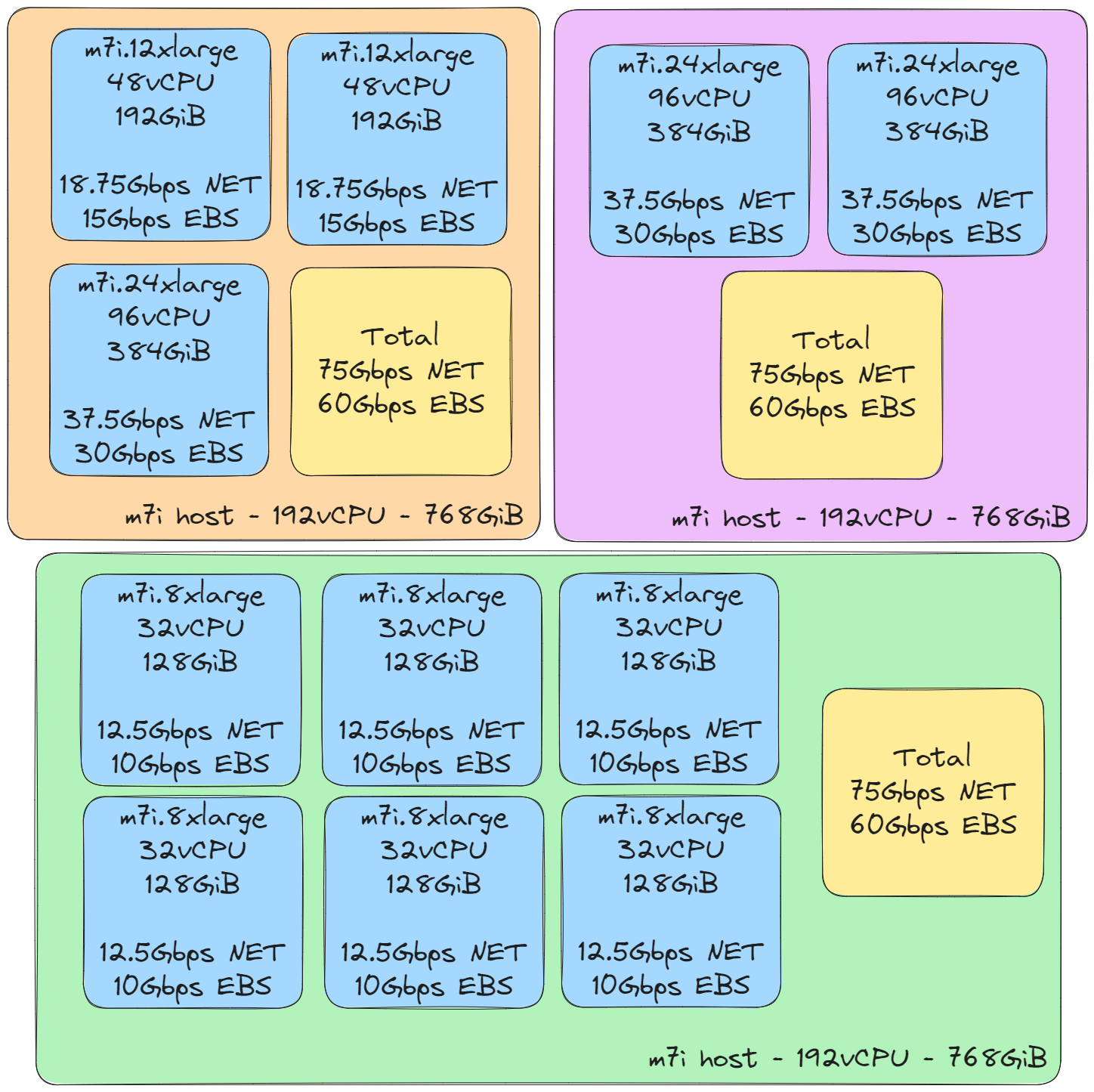
While the details are not public nor helpful when deciding which compute to use, AWS could be deploying these hosts made up of:
- 2x Intel(R) Xeon(R) Platinum 8488C CPUs
- 384GiB (c7i) RAM / 768GiB (m7i) RAM
- 75Gbps Network Bandwith
- 60Gbps EBS Bandwidth
- Additional supporting Nitro Hardware
New to the latest generation of instance types are the multiple bare-metal options available, for example, m7i.metal-24xl and m7i.metal-48xl. Of interest here is the metal-24xl type, which provides half of the expected underlying machine. This is likely made possible via a significant breakthrough with nitro technology, allowing physical dual-socket hardware to be split into two isolated bare metal machines. This would allow AWS to deploy a full dual-socket host and pass through bare-metal-like behaviour and isolation to 2 separate customers simultaneously in a fully isolated matter - I'm sure there will be some interesting Re:Invent23 talks if this is the case!
Burstable/Flex Instance Types
Burstable instance types such as the t3, t3a, and t4g are all great options for burstable compute workloads, and they are likely instance types you have deployed for dev/test environments. So, how are they different from the instances we've discussed?
Fundamentally, they are still instances. They are scheduled onto an underlying host, but the underlying host is overcommitted regarding CPU, network and memory resources allocated to the guests.
For burstable performance EC2 instances, the Nitro System may employ memory management techniques such as reusing, remapping or swapping physical memory out as virtual memory pages but the system is designed so that virtual memory pages are never shared across instances in the interest of maintaining a strong isolation boundary.
- The EC2 Approach to Preventing Side Channels
The available burstable t3a instance types are shown below, from 2vCPU to 8vCPU.
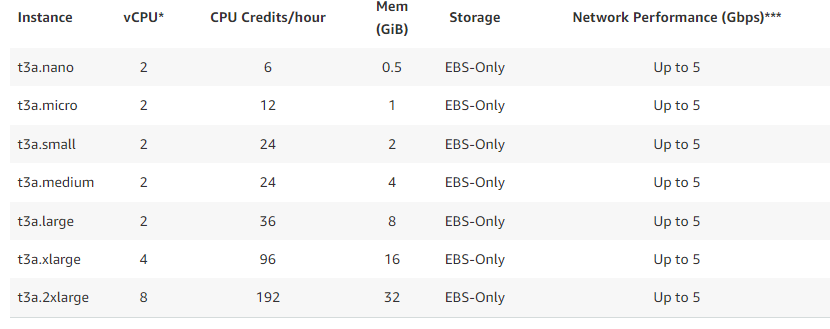
Looking at the baseline utilisation behaviour of these instances, we can see that burstable instance types are only guaranteed up to 40% on an allocated vCPU.
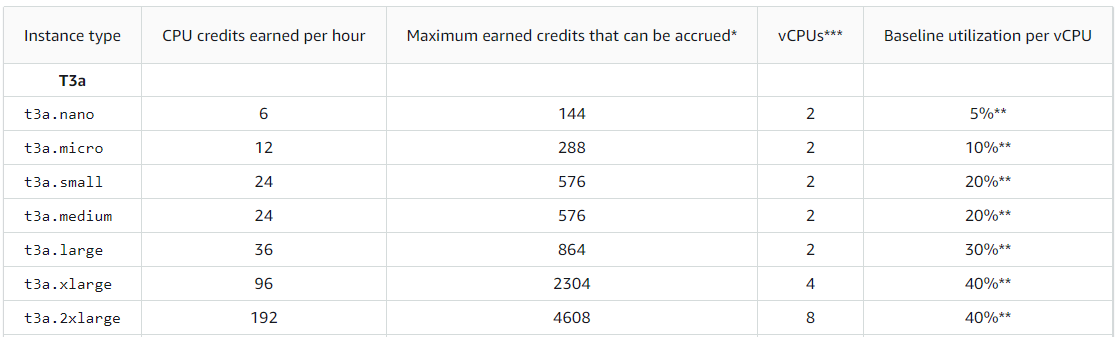
As we know that the CPU and Memory of burstable instances are overcommitted, it's impossible to accurately predict which underlying host sizes are used internally based on public knowledge. However, for the t3a instance type, we know the EPYC 7571 CPU is used, most likely in a dual-socket configuration, providing a guaranteed 96vCPU for allocation. Additional memory and NVMe SSDs (for page swapping) are likely incorporated to allow the maximum host CPU allocation.
For example, taking a t3a.2xlarge with 40% of guaranteed CPU, we can use this information to predict the overall required memory of a potential host, assuming the hosts are fully packed:
96 host vCPU / 0.4 baseline = 240 guest vCPUs
240 guest vCPU / 8 vCPU = 30 t3a.2xlarge instances
30 t3a.2xlarge instances * 32GiB = 960GiB RAM
In reality, based on various workload performance characteristics, the calculated values are likely lower due to factors such as available network, EBS throughput and % of memory overcommit. As a cloud operator, it's vital to make as much of the provisioned compute resources available to customers; otherwise, hardware is sitting unused, ultimately costing money.
As seen, t3a and other burstable instance types are on hosts where the CPU is overcommitted, and they are only guaranteed to provide a consistent baseline performance. In reality, the guest instances running on these nodes don't use all the CPU allocated, nor do they use all of the baselines 100% of the time; this spare unused buffer gives rise to the "burstable" functionality governed by a credit system to ensure fairness across customers.
Instances running on these hosts can have up to 40% CPU guaranteed; however, going over that value is provided on a best-effort basis, even if you pay for it (unlimited credits). Guest instances can measure the best-effort side effect by a kernel metric called 'CPU Steal' (st%), which measures the time a virtual machine waits for its desired CPU resources. In addition, possible memory overcommit by the Nitro Hypervisor may cause a hit in performance for some memory-intensive burstable workloads.
Lastly, separate burstable instances can never share the same physical CPU core at the same time, and the Nitro Hypervisor "utilizes a number of safety strategies at each context switch between instances to ensure that all state from the previous instance is removed prior to running another instance on the same core(s)". Unlike fixed-performance instances, burstable instance types are not pinned to CPU cores. Instead, they "may be rescheduled on different cores than previously used, further limiting the possibility of any kind of successful timing-based security issue."
See the Burstable Credits Baseline Concepts documentation for more information about the burstable credit system and The EC2 approach to preventing side-channels for how hypervisor security is handled for Burstable instance types.
Closing Thoughts
This article has discussed the underlying concepts in virtualisation to break apart a physically deployed host into separate virtual instances. Whilst this understanding is in no way required to use AWS services (or other cloud providers, for that matter), I find such analysis of services fascinating, and it allows me to understand how things work from the ground up, which I find vital for high-level conceptual understanding across multiple technical domains.
The new trend of AWS instance types powered by Nitro seems to be shipping consistent CPU hardware for specific generations and then using the flexibility of Nitro to change specific capabilities, such as enhanced networking or local SSDs.
It will be interesting to see how Nitro develops further in the coming years to enhance the customer's experience. On other cloud providers such as Oracle OCI or GCP, the platforms give customers the right-sized options of choosing CPU and Memory using a slider; for example, for an Oracle E5 Flex instance, you can:
- Choose between 1 and 94 OCPU (physical cores)
- Choose between 1GB and 1049GB RAM (1GB minimum per CPU)
- Allocated 1Gbps dedicated networking up to 40Gbps
This model allows customers to choose truly 'right-sized' instances for their workloads rather than AWS's current t-shirt-sized instance types. Whilst this greatly complicates efficient bin-packing of resources, I believe the value to the customer is two-fold; firstly, customers can pay for exactly what they want, and secondly, it greatly simplifies the number of instance types available (after all, is it that 700 instance types is impressive, or just a vanity metric?) for example:
- m7a instance hardware might be called 'flex.7a'
- Customers no longer need to understand c, r, m or other instance types
- Customers choose the underlying CPU generation type '7a'
- Customers choose the required CPU and Memory
- Customers could opt into other enhancements such as enhanced networking or block volumes (which might have stricter rules to ensure good bin packing)
- AWS still deploy the same (or larger) types of physical hosts
Maybe we will see this one day.
Consider subscribing to stay tuned to future posts!
Further Reading

Heterogeneous bin-packing onto EC2 Dedicated Hosts

How Nitro delivers virtualisation securely