Asset Delivery and Analytics

It's easier than ever to design and run web-scale platforms at a fraction of the cost of what was possible decades ago; however, designing for scale with new technologies sometimes requires a mindset shift to unleash the full potential of the cloud.
In this article, we'll discuss some core architectural challenges in designing an asset distribution platform with a basic analytics backend.
First, let's start with a fictitious scenario:
A gaming company FooBar Mobile creates whitelabel mobile games which are resold to businesses. The games are distributed to end-users inside mobile apps and progressive-web-apps (PWAs). Currently all games are bundled and shipped to the reseller, however, as the game portfolio has grown, these bundles have grown larger and larger.
FooBar Mobile wants to explore a solution where assets can be delivered to gamers just-in-time, reducing initial game launcher installation size.
The requirements of the platform can come from business-related or technical concerns. It's always worth critiquing requirements as part of a design and development process. Typically, requirements do not come with a clear priority, and focus can drift to specific requirements based on the experience of the designer and implementer.
A - The platform SHOULD have near-100% uptime (any outage will cause game launch failures for players, costing resellers money)
B - The platform MUST record analytical data on the usage of game assets (examples include Game Name, Game Version, SDK Version)
C - The API to fetch assets MUST provide a lookup endpoint, allowing for future backend refactoring without having to update client libraries/SDKs
D - The API MUST include endpoints to query data for analytical and operational decision-making
The Initial Design
With the initial background and requirements set, we can start a design. While it might be tempting to jump straight into implementation for an MVP, it's well worth taking a step back and looking deeper as to what is required.
Before putting too much effort into design constraints, note down the simplest solution, so you can identify friction or ambiguity with the defined requirements.
It's likely by now you've thought of a couple of components to implement a system to meet the given requirements using traditional API design techniques. It might look something like this:
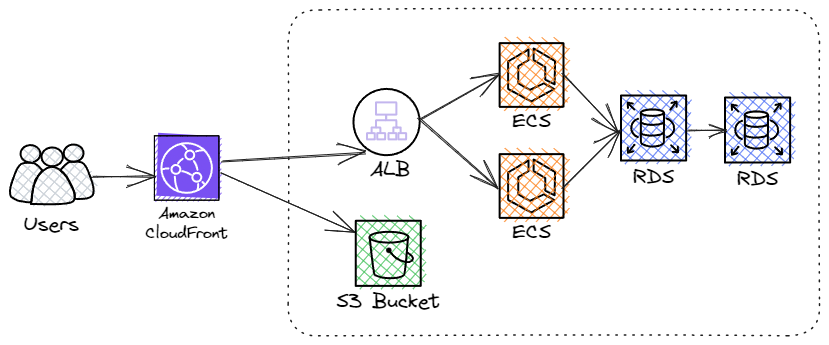
In this design, the mobile app will first make a request to the API https://api.foobar.com/v1/<game>/<version>. We may include additional parameters, such as User Agent, for analytics. The API then records this request (e.g. increment a counter) in a database for analytical purposes and returns a JSON payload with a CDN URL, for example: https://assets.foobar.com/v1/<game>/<version>/assets.bundle.
The flow described above satisfies the following requirements:
B - The platform MUST record analytical data on the usage of game assets (examples include Game Name, Game Version, SDK Version)
C - The API to fetch assets MUST provide a lookup endpoint, allowing for future backend refactoring without having to update client libraries/SDKs
However, without significant engineering challenges, the above design will quickly struggle to achieve perhaps the most critical requirement:
A - The platform SHOULD have near-100% uptime (any outage will cause game launch failures for players, costing resellers money)
Let's consider a subset of possible reasons requests could be interrupted with this approach:
- The API goes down - a bad code push, a faulty load balancer node, a failed instance, or regional interruption can disrupt user access
- The DB goes down - with RDS Proxy, failover downtime can be minimal, however, you are still dependent on the DB to serve requests (saving analytical information)
- Failure to scale - As the API is now in the critical path, scaling of both the API and DB is critical to a successful game load
Some common engineering solutions to the above issues could be:
- Canary releases (validating the deployment and rolling over traffic)
- Multi-AZ + Multi-Regional deployments
- Autoscaling
- Serverless Auto-Scaling databases (e.g. DynamoDB/Aurora V2)
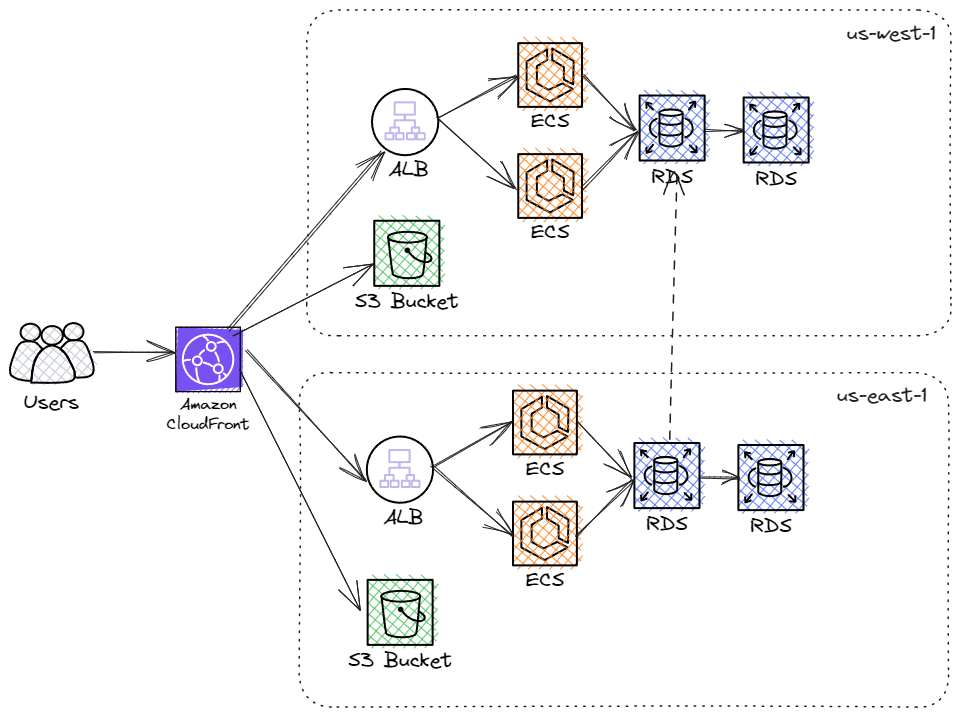
All of these solutions will help the availability requirement but will undoubtedly engage several engineers and require a significant budget to achieve a truly near-100% uptime system. Here is an example of such a solution, which we will discuss further at the end of the article.
Cloud Scale Patterns
We can take a few design ideas from cloud workloads to design this system with minimal operational overhead. Taking the time to learn and implement these techniques can greatly improve the availability of your system while significantly reducing operational costs and complexity.
They are:
- Compute @ Edge

- Data plane + Control plane

- Asynchronous Processing
Compute @ Edge
'Serverless' computing is all the rage at the moment, and CDN providers from the likes of Amazon CloudFront, CloudFlare and Fastly all allow you to run code at the CDN edge.
Such functionality allows requests to be handled by hundreds of points of presence (POP) around the world. Amazon CloudFront now boasts over 400 isolated POPs, resulting in less latency to your customer and less work for your team to maintain a high uptime requirement.
You wouldn't run your own CDN, or your own object store, so why deploy a compute cluster for a simple API endpoint.
If your API endpoint is simple enough to be wrapped up into a small function, moving your compute workload to the edge can be a great advantage. Such use cases can be:
- Cache-key manipulation
- URL rewriting and redirects
- Simple logic
In the API example we outlined above, we want to map the user's request into a known structure, The operation simply involves parsing the parameters and rewriting them into a URL which can then be requested by the client.
https://api.foobar.com/v1/<game>/<version>
Returns:
{"url": "https://assets.foobar.com/v1/<game>/<version>/assets.bundle"}
or
302 Redirect
Location: https://assets.foobar.com/v1/<game>/<version>/assets.bundle
This is a perfect fit for edge functions.
Data plane + Control plane
The idea of splitting your workloads into data/control planes has shown great success at AWS.
This concept comes from networking hardware, where the data plane is responsible for packet forwarding, while the control plane is responsible for high-level decisions and functionality.
In our software design, the data plane is responsible for handling critical requests, comprised of less complicated components and fewer moving parts than the control plane. The control plane, on the other hand, is responsible for complex business logic and orchestration. As you can imagine, control planes are significantly more likely to fail.
Amazon CloudFront is a great example. The control plane exists in the us-east-1 region, where you make management API calls to control your distribution configuration. The control plane then pushes the configuration out to the data plane POPs around the world.
Splitting your application into data and control planes can have the additional benefit of isolated, deployable components. Allowing for improved iteration, less risk and thus a faster time to production.
We can revisit the scenario and identify where we could make this split, and for this, we will focus on where the near-100% uptime requirement is specifically needed. After further clarification with the client, you might find the following is likely:
E - The platform MUST have near-100% uptime for game launch requests
F - The platform SHOULD have 99% uptime for analytical/administration workloads
This clarification suddenly makes the border between planes and functionality clearer. The core purpose of this system is the delivery of assets; that is to say, the critical path relies on the response of an endpoint and the delivery of the asset to the end user. Everything else can be considered secondary and is only to aid in this core objective.
As such, we can define our workloads into two components:
- Data plane - responsible for endpoints concerning game asset downloads
- Control plane - responsible for log/metric aggregation, asset orchestration tooling and analytics
Asynchronous Processing
In the initial design specification, analytical data was stored when the API request was made. This could be as simple as incrementing a counter in a relational database or storing information in a NoSQL or Timeseries datastore. However, this coupling, as we identified above, is a secondary requirement to a user attempting to load an asset.
We can simplify our design by utilising an asynchronous pattern for our metric collection. This single change can allow API to be decoupled from the database, and if the API endpoint doesn't need the database, it can easily run at the edge.
Using AWS CloudFront, the system can take advantage of asynchronous log delivery to an S3 bucket, and we can process these logs to generate aggregate metric counts and statistics.
Cloud Scale Design
Taking the above ideas into consideration, we can design a system that satisfies all the requirements with minimal complexity, minimal operational overhead and improved flexibility. In fact, the cost and complexity of running this system with near-100% critical path availability has been offloaded to the cloud provider, allowing your team to focus on delivering instead of keeping things online.
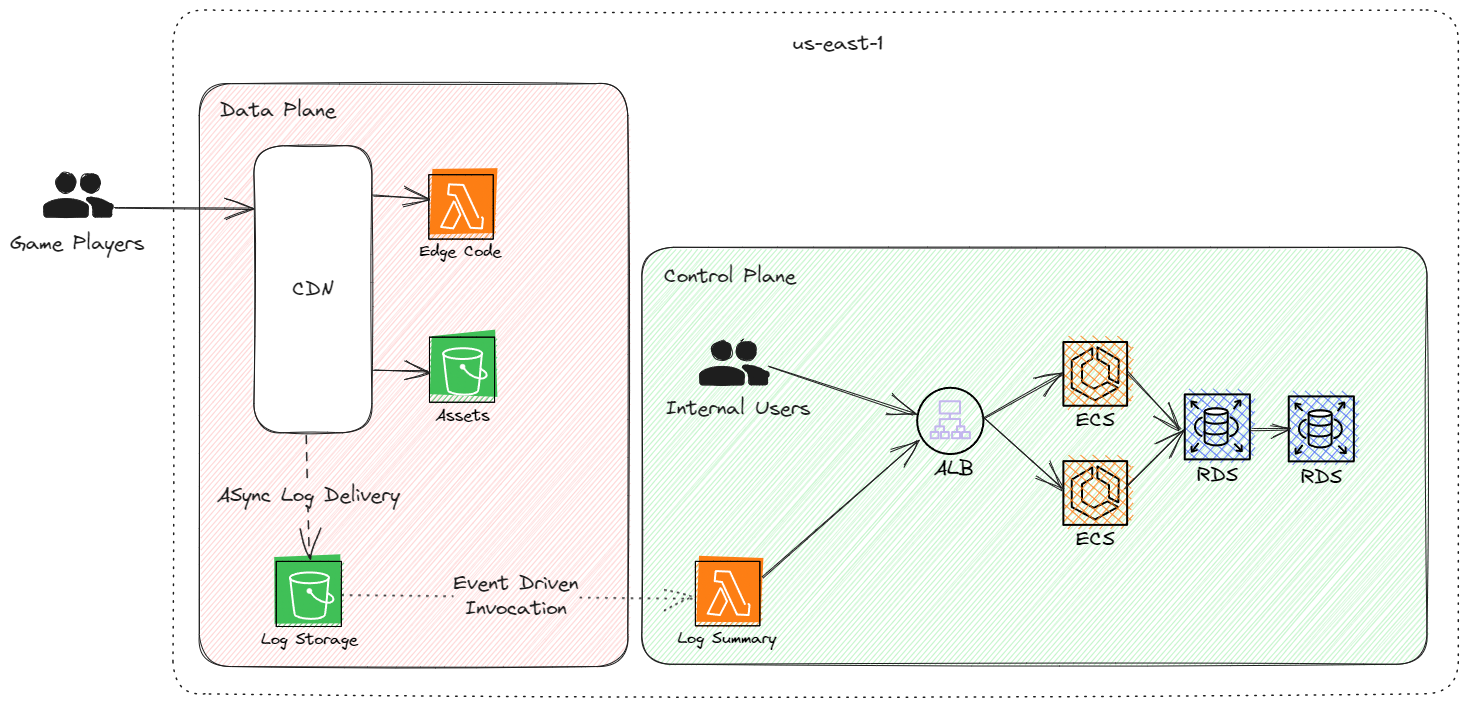
In the above design, the game player still requests from an endpoint to find the asset location (which might not be required in some scenarios). The edge code computes the request based on some static logic and returns a JSON payload pointing to the asset, which the client can then download.
When the client downloads the request, CloudFront logs the request, which makes its way to the Log Bucket. The summarising function reads the logs asynchronously and posts the resulting metrics to the analytics API. The critical path no longer goes via the API running on the ECS compute.
A few design assumptions have been made here:
- Using the same domain for the asset lookup and download - when an HTTPS client connects to the CDN, it will typically create a connection pool per SNI hostname. Keeping the domain the same allows socket reuse, improving the time-to-first-byte (only a single TCP setup is required) of the asset bundle.
- The data plane has no dependencies on the control plane - the edge code, asset bucket and log storage bucket are all part of the data-plane deployment and have no dependencies on the control plane. This allows the control plane to have a complete outage without affecting game players. The aggregation is asynchronous and does not affect the critical path.
- Log delivery is asynchronous - Modelled here is an event-driven lambda function from the data plane deployment into the control plane deployment. This could be worker processes in an ECS deployment if required. The cross-over of planes here allows the control plane to manage log summary logic; remember, the data plane should be as minimal as possible and have few moving parts. Log aggregation is not a critical path requirement. Ensuring this logic is part of the control plane allows for faster iteration as the data plane changes less - all the risk is moved into the control plane, which has fewer availability requirements.
Advantages of this solution:
- Scalability - In the initial design, the entire API had to scale to serve requests. In this design, the scaling technicalities have been offloaded to the CDN provider. If log processing falls being, the control plane can scale up workers or use other methods to handle requests. The scaling of the API and the critical path has been fully decoupled and allows considerable scale at minimal cost.
- Availability - The critical path no longer depends on an API running complicated logic, analytical workloads or other oddities. Instead, the critical path, in this scenario, is completely managed operationally by the CDN provider. Treating the data and control plane as separate deployments allows for safer deployment rollouts. Your API will fail at some point.
- Cost - To guarantee an API to near-100% availability, multi-region compute is a must. With this design, there is no need to run across multiple regions, as your critical path is doing that already. Additionally, as log aggregation is now performed in batches, fewer concurrent writes are required to the database, minimising database costs.
- Flexibility - Using multiple CDN origins, this design is still highly flexible for future adaptation. If more complex API calls are required in the future to facilitate the data plane operation, a dedicated data-plane API can be deployed. Data plane operations should be as simple as possible.
The above ideas should highlight the advantages of thinking deeper about the operational requirements of workloads. Can you think of workloads you maintain that could be split up in such a way?
Further Considerations
The design can also be scaled based on various requirements; for example, let's consider a new requirement:
G - Personal Identifiable Information (PII) of customers must be in stored in an approved region. US resellers customer information MUST be stored in us-east-1. EU resellers customer information MUST be stored in eu-central-1.
We could expect:
- PII is specifically targeting the IP address of the customer downloading the asset. Logs must be stored in the relevant regions where the information is personally identifiable.
- CloudFront does not support multiple log destinations, so we would need multiple distributions to isolate the traffic.
- The requirements explicitly state the traffic MUST be stored in the relevant region, in which case, the SDK must be configured to point to US or EU domain names. An argument can be made here to use Route53 Geo-IP Routing and have an API in the relevant regions, however, Geo-IP routing is the best effort, so a customer could be routed to the wrong region and have their PII logged there.
An explicit definition in SDK configuration is the safest way to satisfy data protection laws.
Building out our control-plane/data-plane pattern, it scales nicely. It would even be possible to scale this system on a per-reseller basis, however, tradeoffs on cache hit ratios and deployment counts and complexities should be considered.
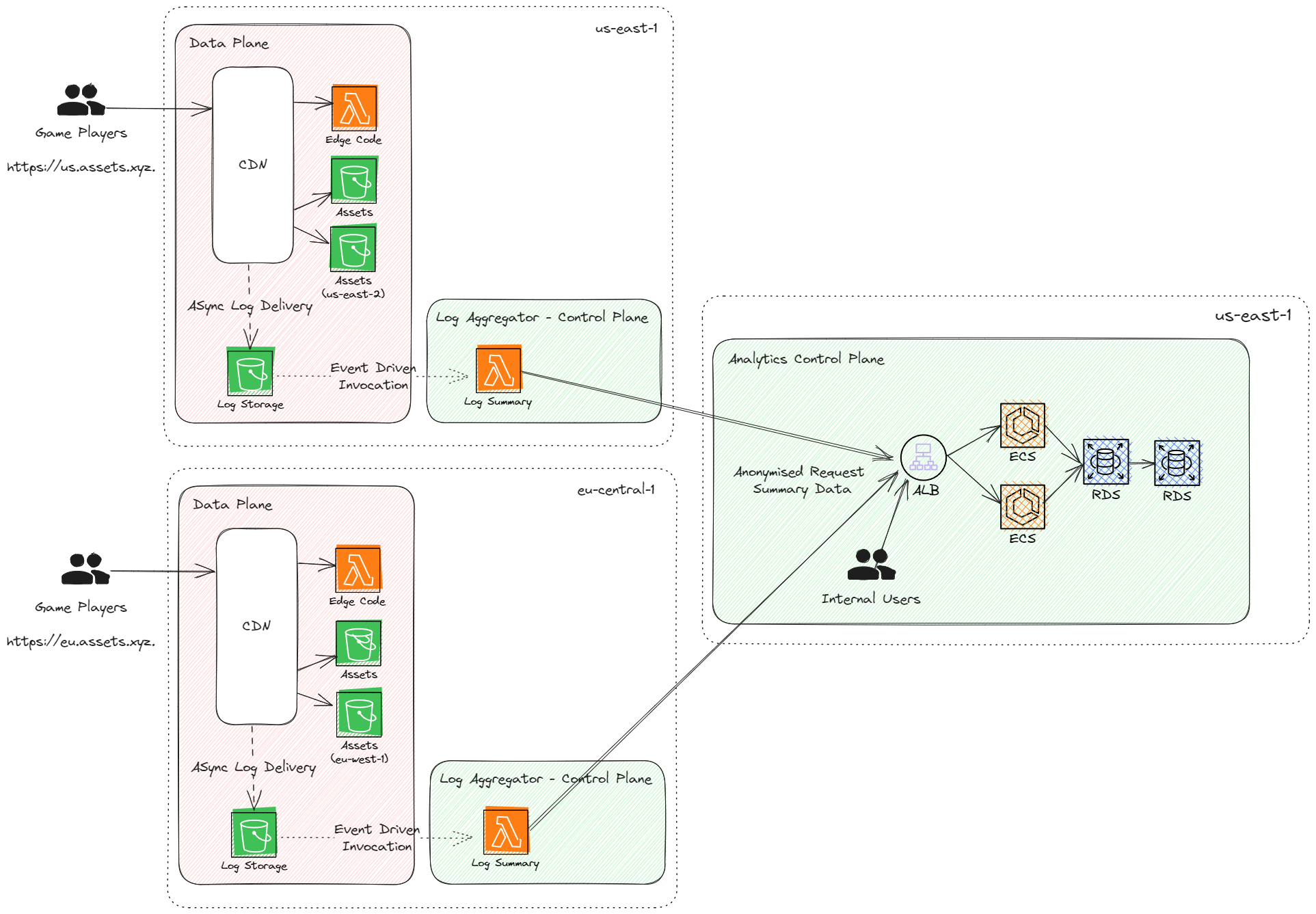
A change from the first cloud design is the move of the log aggregator into the relevant region. To keep the data local, we deploy a new control-plane component for this purpose. This is a control plane component as it has a direct dependency on the central control plane and is not a critical functional component of the critical request path (data planes should not depend on the control plane). It also allows isolated deployments, which have the advantages previously mentioned.
Additionally, we utilise CloudFront Origin failover and have two buckets in each region to prevent an S3 outage in a specific region (typically an internet-crippling event) from affecting our workload.
Compared to the original design, this solution leaves you with a single control plane, greatly simplifying the operation of the platform.
With these additional limiting requirements, let's consider what a traditional combined API system might look like to satisfy the laid-out data residency laws.
We can make the (sensible) assumption that for suitable uptime guarantees, 2 regions are required per continent, with Amazon CloudFront origin failover configured for both the API and bucket.
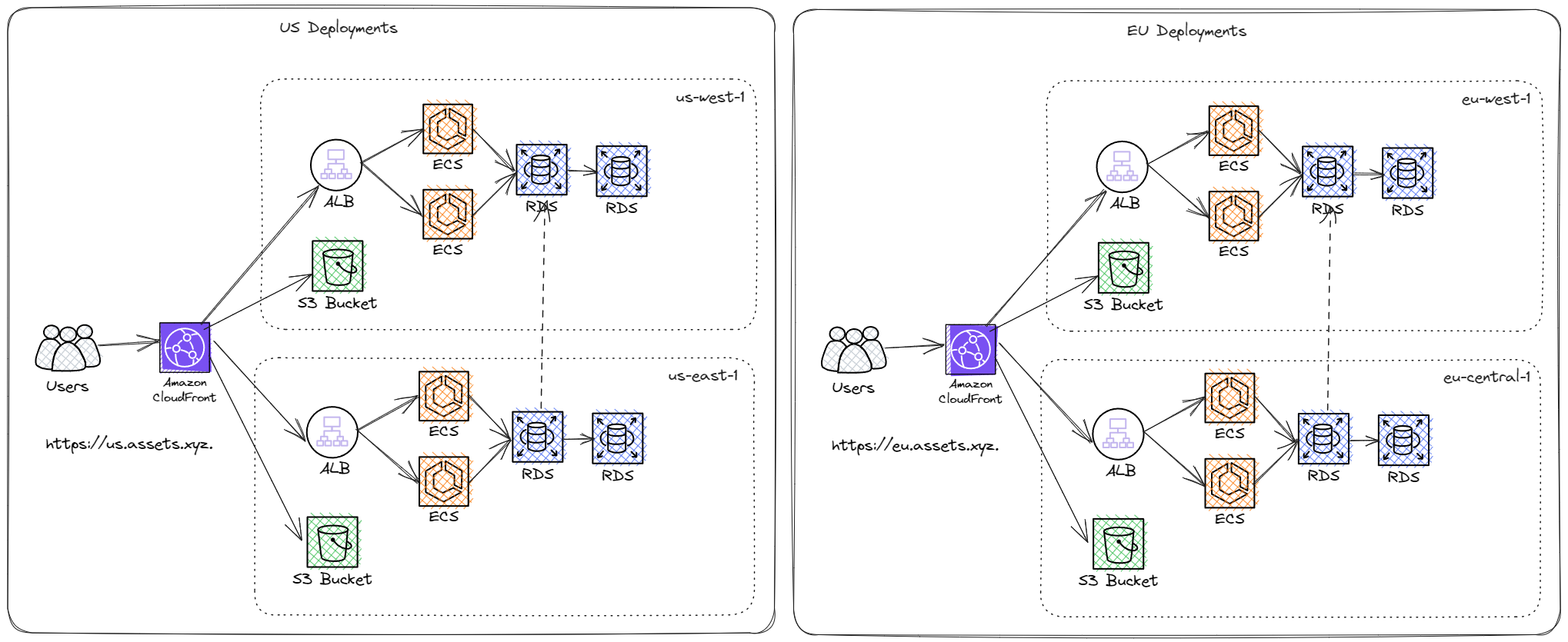
This system explodes with complexity as multiple deployments are added. Additional considerations need to be considered, such as:
- Scaling of the API in every region
- Scaling of the DB in every region
- Cross-region DB replication/write redirection (which has non-trivial caveats)
- Deployments to every region (canary rollouts, etc.)
- API/DB alarms are typically critical on-call pager incidents
Wrapping Up
This article highlights some scalable cloud solutions, including viewing the architecture as control and data planes, using asynchronous processing to decouple concerns and moving compute workloads to the edge.
It's well worth evaluating your requirements at the design stage to see what you can decouple from a monolithic (or even microservice) API.
Such design ideas can save millions a year in operational costs and complexities by taking advantage of modern design techniques made possible using cutting-edge cloud solutions.